author: Marc Lelarge, course: dataflowr, module: Convolutional neural network
date: June 8, 2021
In the module on CNN, we presented the convolutional layers as learnable filters. In particular, we have seen that these layers have a particular form of weight sharing (only the parameters of the kernel need to be learned). The motivation for restricting our attention to this particular weight sharing comes from a long history in signal processing. Here, we would like to recover the intuition for convolutions from first principles.
So let's pretend, we do not know anything about signal processing and we would like to build from scratch a new neural network taking as input an image and producing as output another image. For example in semantic segmentation, each pixel in the input image is linked to a class as shown below (source: DeepLab): 
Clearly in this case, when a object moves in the image, we want the associated labels to move with it. Hence, before constructing such a neural network, we first need to figure out a way to build a layer having this property: when an object is translated in an image, the output of the layer should be translated with the same translation. This is what we will do here.
Here we formalize our problem and simplify it a little bit while keeping its main features. First, instead of images, we will deal with 1D signal of length : . Now translation in 1D is also called a shift: corresponds to the shift to the right. Note that we also need to define in order to keep a signal of length . We will always deal with indices as integers modulo so that and we define . Note that we can write as a matrix:
The mathematical problem is now to find a linear layer which is equivariant with respect to the shift: when the input is shifted, the output is also shifted. Hence, we are looking for a matrix with the shift invariance property:
There is a simple way to approximate a shift invariant layer from an arbitrary matrix : start from and then make it more and more shift invariant by decreasing . When this quantity is zero, we get a shift invariant matrix.
Here is a gradient descent algorithm to solve the problem:
coded in Julia:
using LinearAlgebra, Zygote, Plots
const n = 100
S = circshift(Matrix{Float64}(I, n, n),(1,0))
function loss(W)
norm(W*S-S*W)/norm(W)
end
function step!(W;lr=0.003)
# computing current loss and backprop
current_loss, back_loss = pullback(w -> loss(w),W)
# computing gradient
grads = back_loss(1)[1]
# updating W
W .-= lr .*grads
end
W = randn(n,n)
W ./= norm(W)
# producing the gif
@gif for i=1:10000
step!(W)
heatmap(W,clims=(-0.03,0.03),legend=:none,axis=nothing)
end every 100Below is the corresponding heatmap showing the evolution of the matrix when we solve this problem by a simple gradient descent and starting with pure noise: 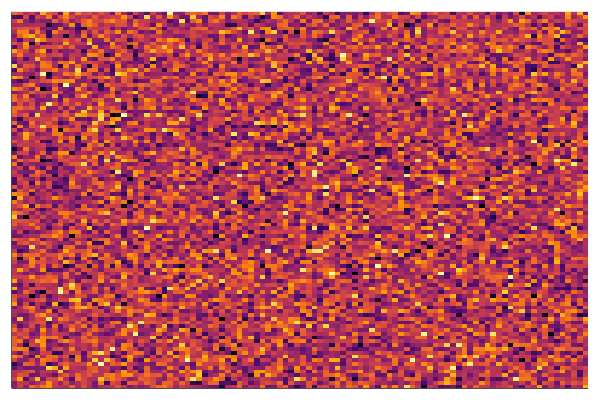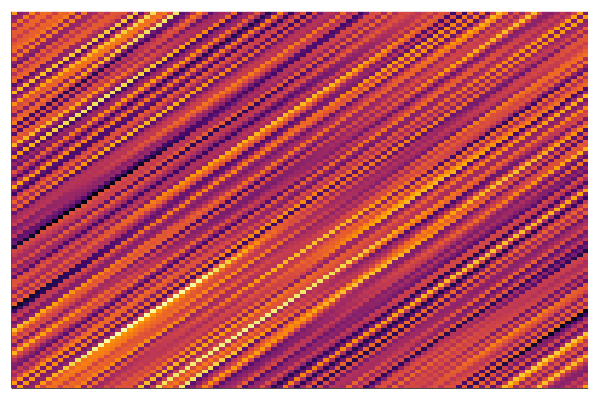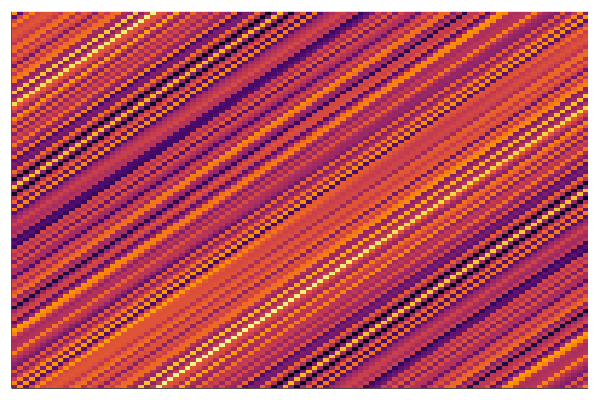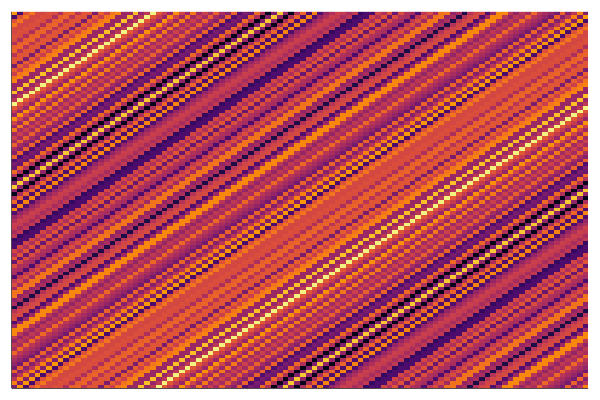
We see that the final matrix has a very strong diagonal structure and we show below that this is the only possible result!
Given a vector , we define the associated matrix whose first column is made up of these numbers and each subsequent column is obtained by a shift of the previous column:
Note that the 'th entry of is given by (remember that indices are integer modulo ). In particular, the left (right) multiplication by amounts to row (column) circular permutation, so that we easily check that for any circulant matrix , we have .
Now to finish the proof of the proposition, note that
so that we get
Hence the matrix needs to be constant along diagonals which is the definition of being a circulant matrix:
where is the first column of , i.e. .
What is the connection with convolution? Well, note that so that we have for :
which is the definition of a 1D-convolution:
It is now easy to check that the product of two circulant matrices is another circulant matrix and that all circulant matrices commute. This last fact has important consequences. We illustrate it here by presenting a simple general result: consider a matrix with simple (non-repeated) eigenvalues so that
Now if commutes with , observe that
so that is an eigenvector of associated with eigenvalue . Since those eigenvalues are distinct, the corresponding eigenspace is of dimension one and we have . In other words, and have the same eigenvectors. If is the matrix where the columns are the eigenvectors of : , then we have
and and . The matrices and are simultaneously diagonalizable.
In summary, if we find a circulant matrix with simple eigenvalues, the eigenvectors of that circulant matrix will give the simultaneously diagonalizing transformation for all circulant matrices.
There is a natural candidate for a "generic" circulant matrix, namely the matrix of the shift . Instead, we will deal with so that we'll recover the classical Discrete Fourier Transform (DFT). Since , we have
Taking, we get: and since , there is at least one index with so that : any eigenvalue of must be an -th root of unity , for . Using (13), we get for the eigenvector associated with :
but since is a scalar and can be defined up to a multiplication, so that we can set for a more compact expression for the eigenvector. Note that , so that we proved:
Since a circulant matrix commutes with , we know from the discussion above that are the eigenvectors of and we only need to compute the eigenvalues of from the relation: so that
which is precisely the classically-defined DFT of the vector .
If you want to dig further in this direction, have a look at Discovering Transforms: A Tutorial on Circulant Matrices, Circular Convolution, and the Discrete Fourier Transform by Bassam Bamieh.
In this last section, we'll explore what happens when we stack convolutional layers. To simplify the analysis, we will ignore biases and non-linearity used in standard convolutional layers to focus on the kernel size. Typically, the size of the kernel used in practice is much smaller than the size of the image. In our case, this would correspond to a vector with a small support, i.e. only and all others for with much smaller than . Using convolutions with only small kernels seem like a big constraint with a potential loss in term of expressivity.
We now show that this is not a problem and explain how to recover any convolution by stacking convolutions with small kernels. The main observation is that , so that the multiplication of the circulant matrices associated to vectors and corresponds to the circulant matrix of with . In particular, note that if both and have a support of size say , then has a support of size . Indeed, multiplying a circulant matrix associated with a vector of support with a circulant matrix associated with a vector of support will produce a circulant matrix associated with a vector of support , as shown below:
We end this post with a nice connection between convolutions and polynomials. For a vector , we denote
Note that (Side note: if you are interested in algorithms, I strongly recommend this video on The Fast Fourier Transform (FFT) by Reducible explaining how to make this multiplication fast). Here, we are only interested in the fact that stacking convolutional layers, is equivalent to multiplication of the associated polynomials. In particular, we see that the support of the vector is now related to the degree of the polynomial. By stacking convolutional layers with kernel of size , we should be able to approximate any polynomial.
Let's try this in Julia:
using Flux, LinearAlgebra, Polynomials, Plots
const n = 100
# target polynomial
c = ChebyshevT([-1,0,-2,0,1,0,1,2,3])
target = convert(Polynomial, c)
plot(target, (-1.,1.)...,label="target")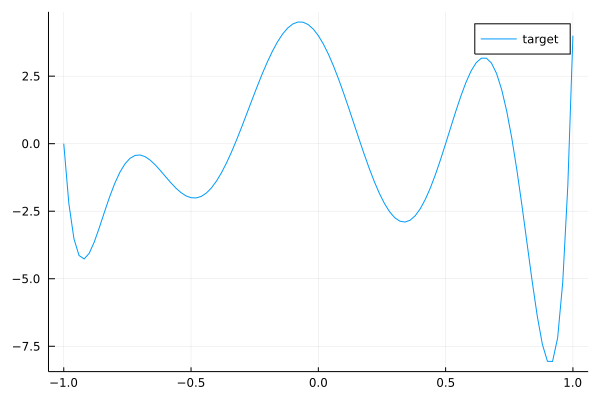
This is our target convolution represented as a polynomial by (17). We can check with the comand length(target.coeffs) that the kernel size of this convolution is 9. Now we will create a dataset made of samples for randoms :
# mapping polynomial to circulant matrix
S = circshift(Matrix{Float64}(I, n, n),(1,0))
param = zeros(n)
param[1:9] = target.coeffs
Circulant = param
for k in 1:n-1
Circulant = hcat(Circulant, S^k*param)
end
# creating dataset with 3000 samples
bs = 3000
x = randn(Float32,n,1,bs)
y = convert(Array{Float32},
reshape(transpose(Circulant)*dropdims(x;dims=2),(n,1,bs))
)
data = [(x,y)]Our task now is to learn from this dataset with a neural network with 7 convolutional layers with kernels of size 3.
# padding function to work modulo n
function pad_cycl(x;l=1,r=1)
last = size(x,1)
xl = selectdim(x,1,last-l+1:last)
xr = selectdim(x,1,1:r)
cat(xl, x, xr, dims=1)
end
# neural network with 7 convolution layers
model = Chain(
x -> pad_cycl(x,l=0,r=2),
CrossCor((3,),1=>1,bias=Flux.Zeros()),
x -> pad_cycl(x,l=0,r=2),
CrossCor((3,),1=>1,bias=Flux.Zeros()),
x -> pad_cycl(x,l=0,r=2),
CrossCor((3,),1=>1,bias=Flux.Zeros()),
x -> pad_cycl(x,l=0,r=2),
CrossCor((3,),1=>1,bias=Flux.Zeros()),
x -> pad_cycl(x,l=0,r=2),
CrossCor((3,),1=>1,bias=Flux.Zeros()),
x -> pad_cycl(x,l=0,r=2),
CrossCor((3,),1=>1,bias=Flux.Zeros()),
x -> pad_cycl(x,l=0,r=2),
CrossCor((3,),1=>1,bias=Flux.Zeros())
)
# MSE loss
loss(x, y) = Flux.Losses.mse(model(x), y)
loss_vector = Vector{Float32}()
logging_loss() = push!(loss_vector, loss(x, y))
ps = Flux.params(model)
opt = ADAM(0.2)
# training loop
n_epochs = 1700
for epochs in 1:n_epochs
Flux.train!(loss, ps, data, opt, cb=logging_loss)
if epochs % 50 == 0
println("Epoch: ", epochs, " | Loss: ", loss(x,y))
end
endBy running this code, you can check that the network is training. Now, we check that the trained network with 7 layers of convolutions with kernels of size 3 is close to the target convolution with kernel size 9. To do this, we extract the weights of each layer and map it back to a polynomial thanks to (17) and then we multiply the polynomials to get the polynomial associated with the stacked layers. This is done below:
pred = Polynomial([1])
for p in ps
if typeof(p) <: Array
pred *= Polynomial([p...])
end
end
plot(target, (-1.,1.)...,label="target")
ylims!((-10,10))
plot!(pred, (-1.,1.)...,label="pred")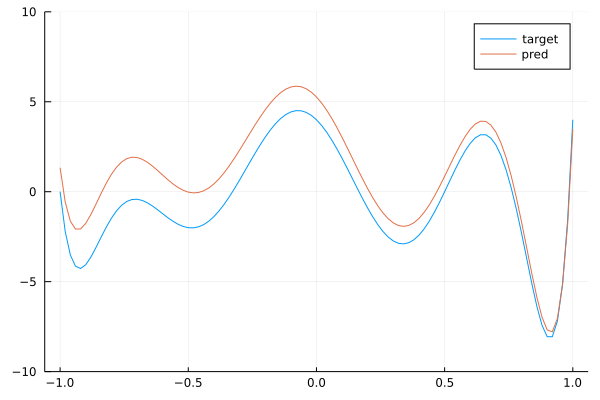
We see that we get a pretty good approximation of our target polynomial. Below is the a gif showing the convergence of our network towards the target:
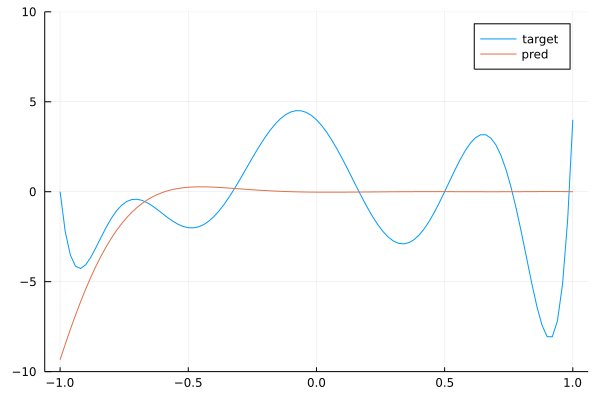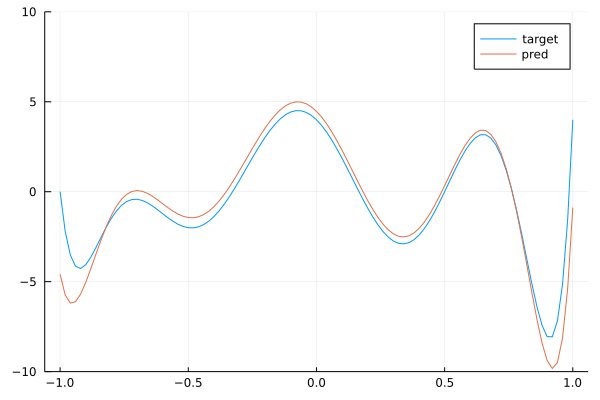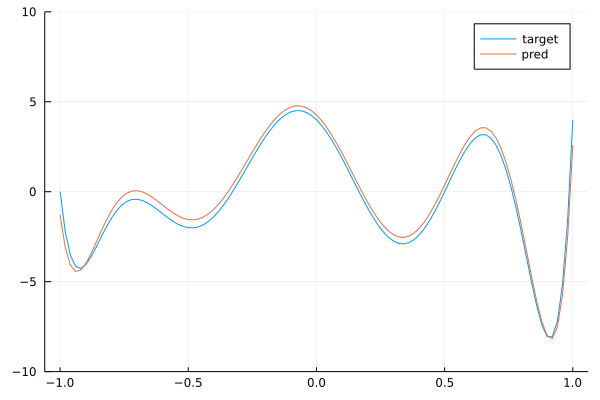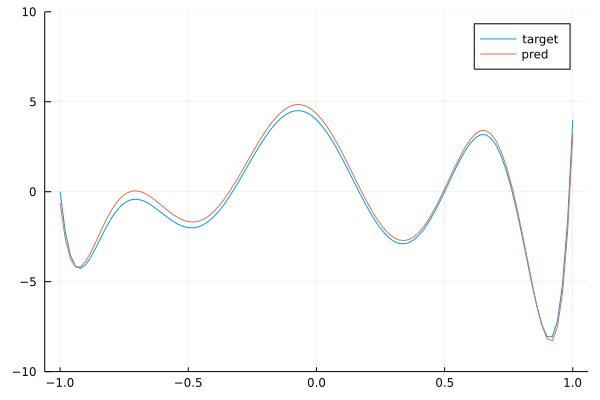
By stacking convolutions with kernel of size 3, we obtained a network with a receptive field of size 9.
Follow on twitter!

